Abstract Data Types (IB CS B4.1, HL): Linked Lists, BSTs and Sets
IB CS B4.1 (HL) explained: what ADTs are, singly, doubly and circular linked lists, binary search trees, and sets, with diagrams, a worked example and exam tips.

You made it: B4.1 is the final subtopic of the IB Computer Science course, and it ties together almost everything you have learned about data and OOP. This whole subtopic is HL only. An abstract data type, or ADT, is a way of describing a data structure by what it does rather than how it works, and the three stars of this topic are linked lists, binary search trees, and sets. Let's finish strong.
What is an abstract data type?
An ADT is defined by its operations, not its implementation. It says: here is a structure you can add to, remove from, search, and traverse, and here is how each operation behaves. What it deliberately does not say is how the data is stored underneath. That could be an array, a linked list, a tree, or something else entirely, and the user of the ADT neither knows nor cares.
This is the same thinking you met in OOP. ADTs combine abstraction (work with what operations do, not how they are coded), encapsulation (data and operations bundled together, internals protected), and modularity (the implementation can be swapped or reused without breaking the code that uses it). A stack is a perfect example you already know: "push and pop at the top" is the contract; whether it is built on an array or a linked list is an implementation detail.

What is a linked list?
A linked list is a chain of nodes. Each node holds two things: a piece of data and a pointer (a reference) to the next node. The first node is the head; the last is the tail.
There are three variants to know. In a singly linked list, each node points only to the next one, and the tail points to null to mark the end. In a doubly linked list, each node points both forwards and backwards, so you can traverse in either direction at the cost of storing an extra pointer per node. In a circular linked list, the tail points back to the head, forming a loop, which suits cyclic jobs like round-robin scheduling where you go around the items again and again.
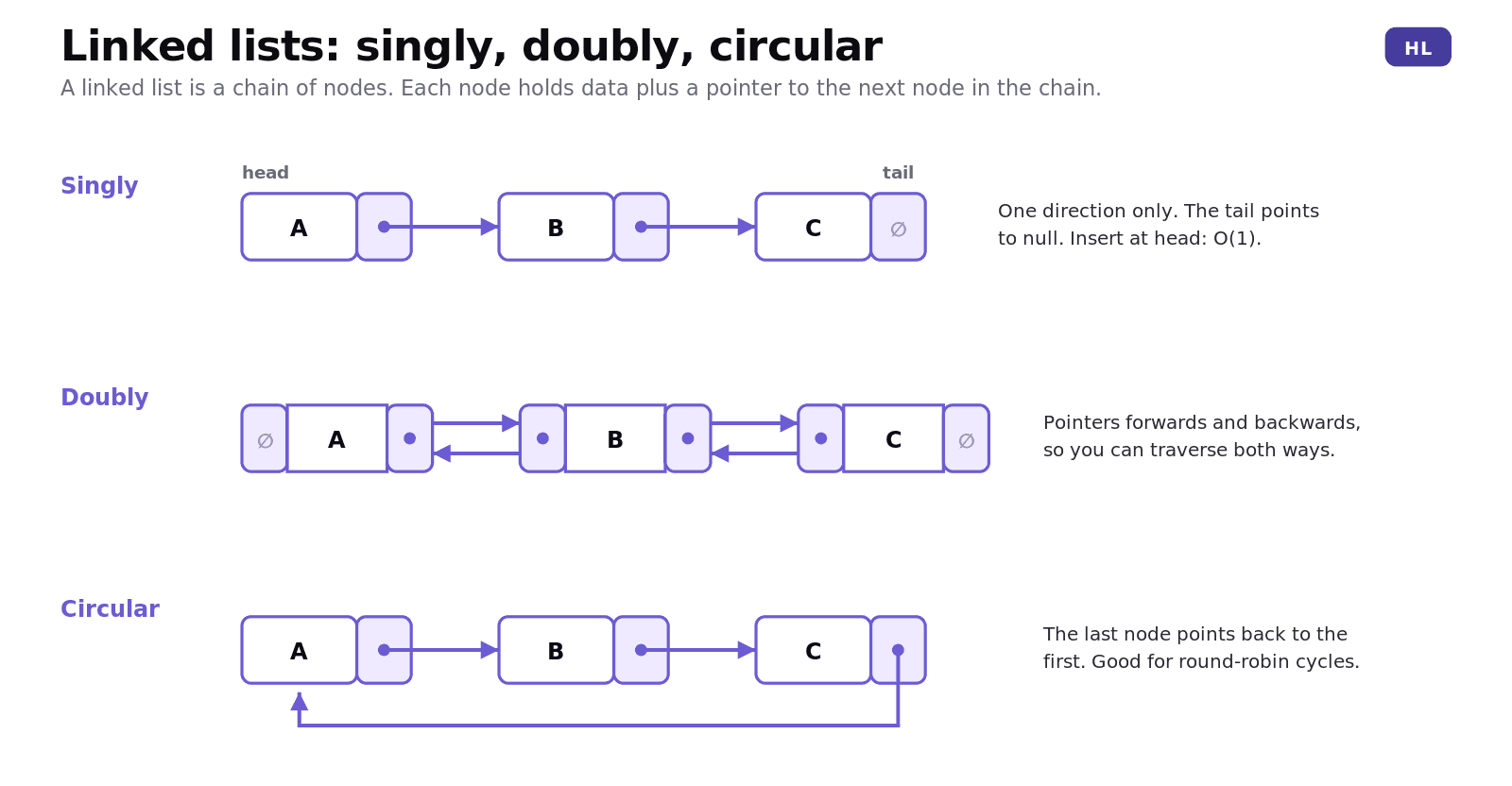
Why use one instead of an array? Flexibility. A linked list grows and shrinks node by node, and inserting or deleting at a known position is O(1) because you just redirect pointers, with no shuffling of elements. The trade-offs: extra memory for the pointers, and no fast random access. To find an item you must walk the chain from the head, which makes search and traversal O(n).
What is a binary search tree?
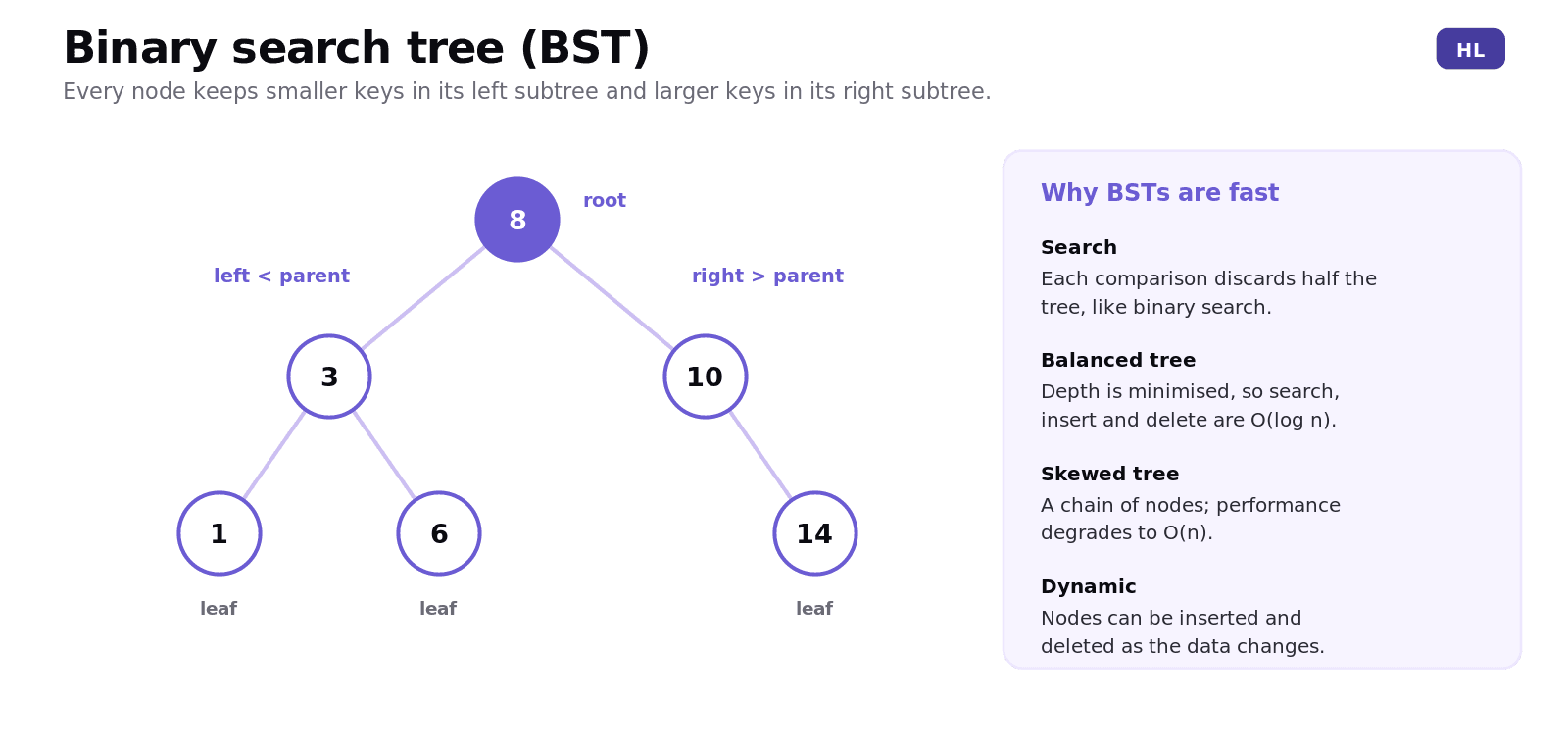
A binary search tree (BST) is a tree of nodes where each node has at most two children, and one strict ordering rule holds everywhere: keys in a node's left subtree are smaller than the node's key, and keys in its right subtree are larger. The topmost node is the root; nodes with no children are leaves.
That ordering rule is what makes BSTs fast. Searching works exactly like binary search: compare with the current node, then go left or right, discarding half the remaining tree at each step. In a balanced tree, where depth is kept small, search, insertion and deletion are all O(log n). Beware the skewed tree though: insert already-sorted data naively and the tree degenerates into a chain, dragging performance down to O(n).
What is a set?
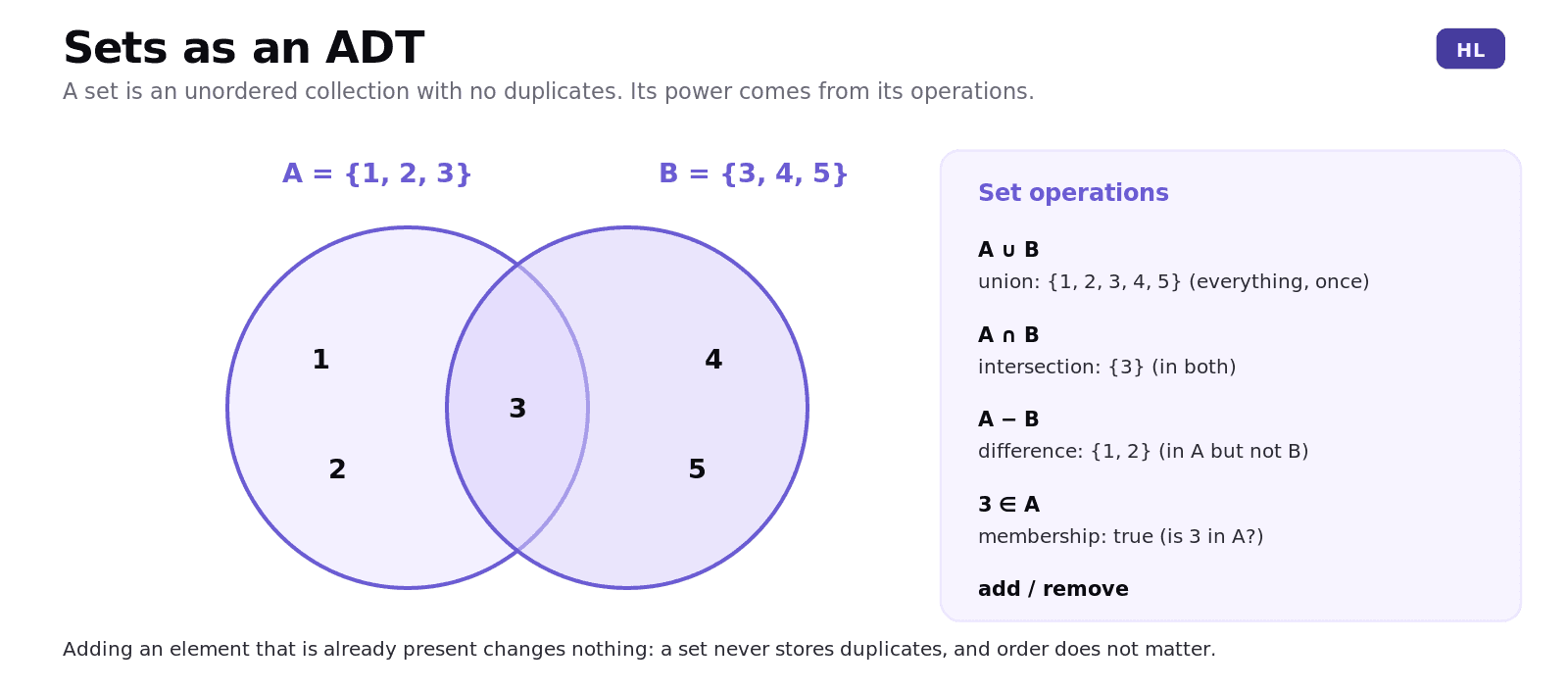
A set is the simplest ADT of the three, and it is defined by two properties: it is unordered, and it contains no duplicates. Adding an element that is already present changes nothing.
Its power is in its operations. Membership asks whether an element is in the set. Union combines two sets into one containing everything (once). Intersection keeps only the elements in both. Difference keeps the elements in one set but not the other. If A = {1, 2, 3} and B = {3, 4, 5}, then A union B is {1, 2, 3, 4, 5}, A intersection B is {3}, and A minus B is {1, 2}. Sets shine whenever uniqueness matters, like collecting the distinct words in a document or the unique visitors to a site.
Worked example: building a binary search tree (HL)
The skill examiners test most here is inserting keys into a BST by hand. Insert these keys, in this order, into an empty tree: 8, 3, 10, 1, 6, 14. The rule at every node is the same: go left if the new key is smaller, right if it is larger.
Trace each insertion, following the comparisons down from the root:
Insert | Comparisons | Placed as |
|---|---|---|
8 | tree is empty | the root |
3 | 3 < 8 | left child of 8 |
10 | 10 > 8 | right child of 8 |
1 | 1 < 8, then 1 < 3 | left child of 3 |
6 | 6 < 8, then 6 > 3 | right child of 3 |
14 | 14 > 8, then 14 > 10 | right child of 10 |
The finished tree looks like this:
Now read it back with an in-order traversal (visit left subtree, then the node, then right subtree). Doing that gives: 1, 3, 6, 8, 10, 14. That is a defining property worth remembering: an in-order traversal of a BST always comes out in sorted order.
Your turn (guided practice). Insert 5 into the finished tree. Where does it land? Follow the rule: 5 < 8 (go left to 3), 5 > 3 (go right to 6), 5 < 6 (go left), and that spot is empty, so 5 becomes the left child of 6.
A worked example: choosing the right ADT
Exam questions love to describe a scenario and ask which ADT fits and why. Try this one: a music app needs three things.
First, a play queue that repeats forever: after the last song it loops back to the first. The structure cycles, so a circular linked list fits naturally; the "next" pointer of the last song simply points back to the first.
Second, a library of 100,000 songs that users search by title, with songs constantly added and removed. You need fast search on dynamic, ordered data: a balanced BST gives O(log n) search, insertion and deletion, far better than scanning a list.
Third, a record of which artists you have listened to, where each artist should appear once no matter how many plays. Uniqueness is the requirement, so a set is the obvious choice; adding an artist who is already there changes nothing, and membership tests are quick.
One scenario, three different ADTs, each justified by matching its defining property to the job. That justification step is exactly what earns the marks.
Common exam mistakes
The biggest one is describing the implementation instead of the ADT. An ADT is defined by its operations and their behaviour; if a question asks what an ADT is, talk about the interface and the hiding of implementation detail.
With linked lists, students often forget what the pointers do: the tail of a singly linked list points to null, a doubly linked list needs both pointers updated on every insert or delete, and a circular list has no null at all.
With BSTs, the classic error is breaking the ordering rule when inserting by hand, or forgetting that the rule applies to entire subtrees, not just direct children. Also remember that O(log n) assumes a balanced tree; a skewed tree is O(n).
With sets, do not add duplicates or rely on order. A set has neither. If a question needs counting of repeats or a fixed sequence, a set is the wrong tool, and saying so (with the reason) is often worth a mark.
Quick recap
This whole subtopic is HL only, and it is the last one in the course. An ADT is defined by its operations (the what); the implementation (the how) stays hidden. Linked lists chain nodes with pointers: singly (one way, tail to null), doubly (both ways), circular (loops back). A BST keeps smaller keys left and larger keys right, giving O(log n) search when balanced, O(n) when skewed. A set is unordered with no duplicates; its key operations are membership, union, intersection and difference.
Frequently asked questions
What is an abstract data type? An abstract data type is a data structure defined by the operations it supports and how they behave, not by how it is implemented. The implementation is hidden, so it can be an array, linked list or tree underneath without changing the code that uses it. This is HL content.
What is the difference between singly, doubly and circular linked lists? In a singly linked list each node points only to the next, and the tail points to null. In a doubly linked list each node points both forwards and backwards, allowing traversal in either direction. In a circular linked list the last node points back to the first, forming a loop. This is HL content.
What are the advantages and disadvantages of linked lists? Linked lists grow and shrink dynamically, and inserting or deleting at a known position is O(1) because only pointers change. The costs are extra memory for the pointers and no fast random access, since finding an item means walking the chain, which is O(n). This is HL content.
What is the ordering rule of a binary search tree? For every node in a BST, all keys in its left subtree are smaller than the node's key, and all keys in its right subtree are larger. This rule lets each comparison discard half of the remaining tree, which is what makes searching fast. This is HL content.
Why does a skewed BST perform badly? A skewed BST forms when nodes chain in one direction, for example after inserting already-sorted data. The tree behaves like a linked list, so search, insertion and deletion degrade from O(log n) to O(n). Keeping the tree balanced preserves its efficiency. This is HL content.
What are the main operations on a set? A set supports adding and removing elements, membership testing (is x in the set?), union (everything in either set), intersection (only what is in both), and difference (what is in one but not the other). A set is unordered and never stores duplicates. This is HL content.
Looking for a printable summary? Grab the Abstract Data Types (IB CS B4.1, HL): Linked Lists, BSTs and Sets, a four-page knowledge organiser covering everything above.
Looking for an IB Computer Science tutor?
Hi, I'm Yuness, the tutor behind Shuttle Learning. I work one to one with IB Computer Science students at SL and HL, and I deliberately take on only a handful each year so every student gets my full attention. Most go on to earn the 6s and 7s they were aiming for, in the final exams and the IA alike.
If you would like that kind of support, book a free 15-minute call and tell me what you are stuck on. You can press BOOK A LESSON .