Machine Learning Approaches (IB CS A4.3): HL Guide
IB Computer Science A4.3 (HL) explained: regression, classification, clustering, association rules, reinforcement learning, genetic algorithms, neural networks, and model evaluation.

This is the biggest topic in Theme A4: the actual algorithms that do the learning. Topic A4.3 is HL only, and it spans regression, classification, clustering, reinforcement learning, genetic algorithms, neural networks, and how to evaluate a model. The trick is to slot each method into its learning type and know what problem it solves.
This guide works through all ten A4.3 understandings, grouped by approach.

What does IB CS topic A4.3 cover?
A4.3 is HL only. It covers linear regression, classification, hyperparameter tuning, clustering, association rule learning, reinforcement learning, genetic algorithms, artificial neural networks, convolutional neural networks, and model selection and comparison. They fall under the three learning types from A4.1, plus techniques (neural networks and genetic algorithms) that cut across them.
How does linear regression work?
Linear regression is a supervised method for predicting a continuous outcome. It models the relationship between an input and an output as a straight line, of the form output = gradient × input + intercept.
Training finds the line that best fits the data, usually by minimising the total squared distance between the line and the actual points. Once fitted, you predict a new value by reading off the line, for example estimating a house price from its floor area.
How does classification work?
Classification is a supervised method for predicting a category. Two methods the syllabus highlights are k-nearest neighbours (k-NN) and decision trees.
In k-NN, a new item is classified by the majority vote of its k closest neighbours in the data. A decision tree splits the data with a series of yes/no questions, ending in a category at each leaf. Trees are easy to read but can overfit if grown too deep, which is why they are sometimes pruned.
Worked example: classifying a fruit with k-NN
Suppose each fruit is described by weight and a colour code, and you have labelled examples of apples and oranges. To classify a new fruit weighing 160 g with colour code 1, k-NN finds the k labelled fruits closest to it (by distance in weight and colour) and assigns the majority class among those neighbours. Choosing k, the number of neighbours, is a key setting.
What is clustering and association rule learning?
These are unsupervised methods that work on unlabelled data.
Clustering groups similar items together without any labels; k-means is the classic algorithm, which assigns points to the nearest of k cluster centres and repeats until the groups stabilise. It is used for things like customer segmentation. Association rule learning finds items that tend to occur together, the engine behind "customers who bought this also bought that", classically applied to market-basket analysis.
How does reinforcement learning work?
Reinforcement learning has an agent that interacts with an environment. The agent takes an action, receives a reward or penalty, and updates its strategy to maximise its cumulative reward over time. There is no labelled dataset; the agent learns by trial and error. This suits sequential decision problems like game-playing AI and robotics.
What are genetic algorithms?
A genetic algorithm is an optimisation method inspired by natural selection. It keeps a population of candidate solutions and improves them over generations using three operations: selection (keep the fittest), crossover (combine two solutions to make offspring), and mutation (randomly tweak a solution). A fitness function scores how good each candidate is. Genetic algorithms are useful for hard search and optimisation problems where the best answer is not obvious.
How do neural networks work?
An artificial neural network (ANN) is made of neurons arranged in layers, joined by weighted connections.
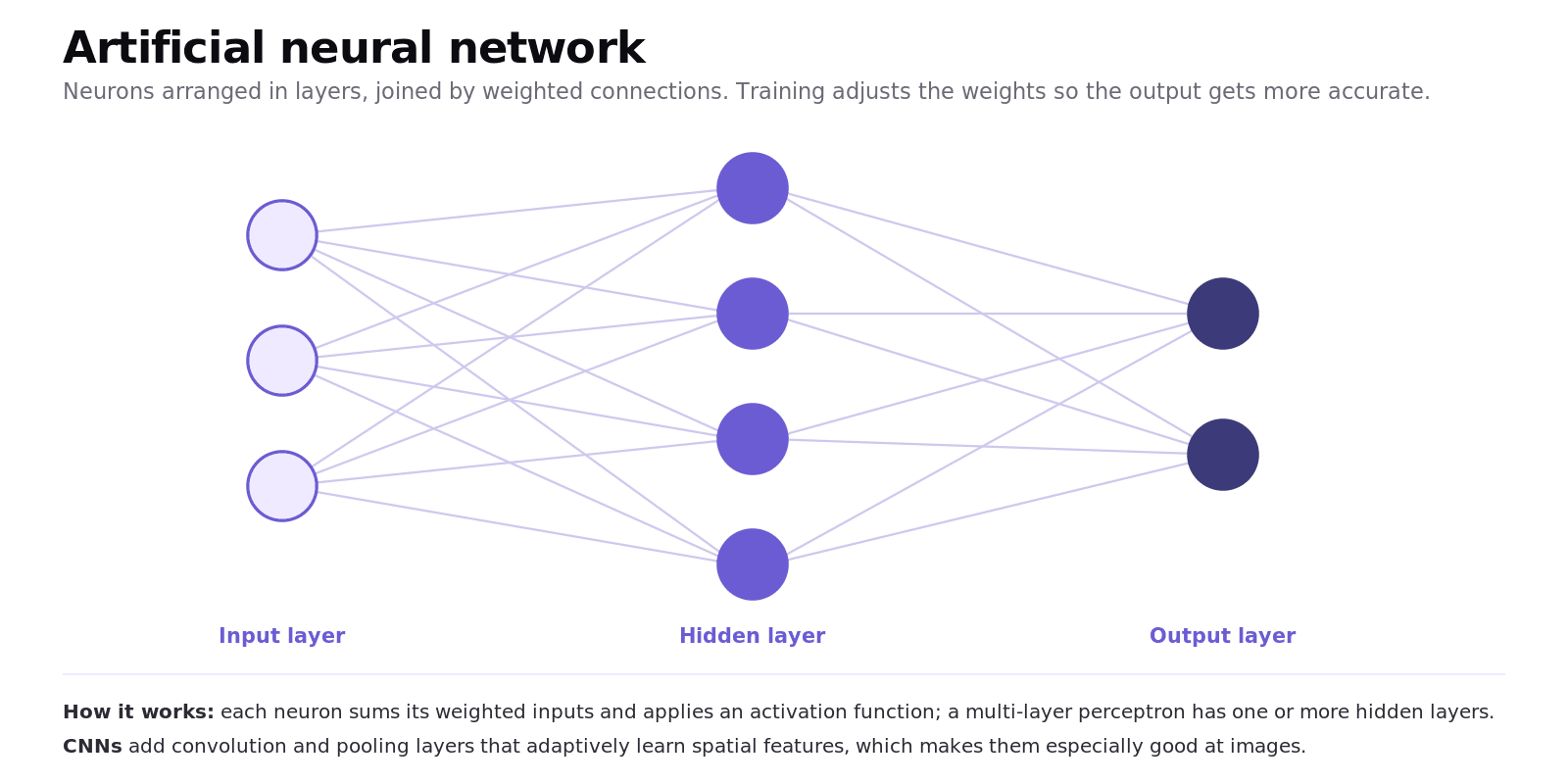
Data enters at the input layer, passes through one or more hidden layers, and produces a result at the output layer. Each neuron sums its weighted inputs and applies an activation function; training adjusts the weights so the output becomes more accurate. A network with one or more hidden layers is a multi-layer perceptron, and using many layers is called deep learning. Convolutional neural networks (CNNs) add convolution and pooling layers that adaptively learn spatial features, which makes them especially strong at image tasks.
How do you evaluate and select a model?
Picking the best model means measuring how well it generalises to new data, not how well it memorises the training data.
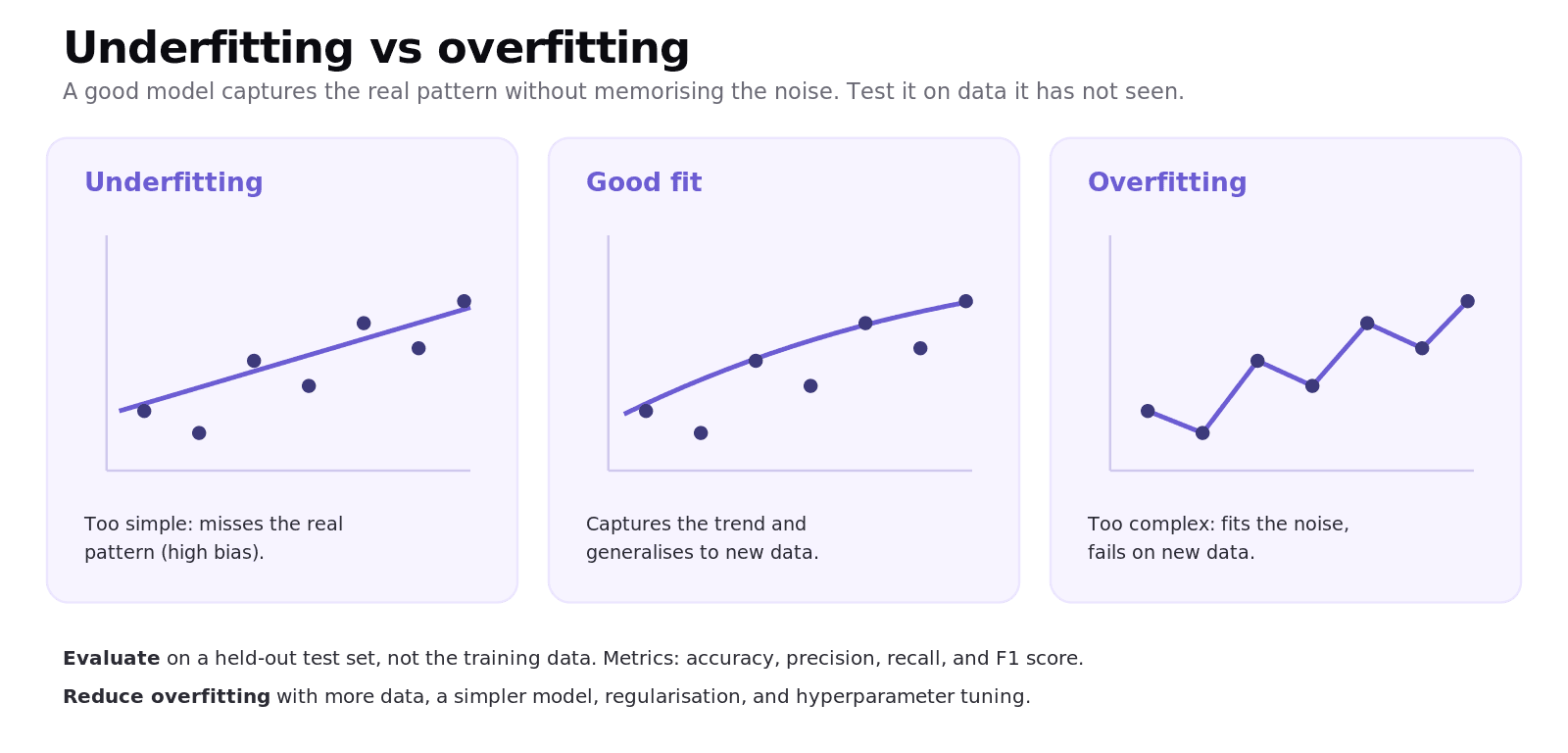
Underfitting means the model is too simple and misses the pattern; overfitting means it is too complex and fits the noise, doing badly on new data. You judge a model on a held-out test set using metrics such as accuracy, precision, recall, and F1 score. Hyperparameter tuning adjusts settings chosen before training (like k in k-NN or the depth of a tree) to find the best version, and model selection compares candidates fairly to pick the strongest.
Common exam mistakes for IB CS A4.3
Confusing regression (continuous output) with classification (categorical output).
Confusing clustering (unsupervised) with classification (supervised).
Thinking a more complex model is always better; complexity causes overfitting.
Mixing up hyperparameters (set before training) with the weights the model learns during training.
Forgetting the three genetic-algorithm operations: selection, crossover, and mutation.
Evaluating a model on the training data instead of a separate test set.
Quick recap of A4.3
Supervised: linear regression (continuous), classification (categories, via k-NN or decision trees), tuned with hyperparameters.
Unsupervised: clustering (k-means) and association rules.
Reinforcement learning: an agent maximises cumulative reward by trial and error.
Genetic algorithms evolve solutions with selection, crossover, and mutation.
Neural networks (ANNs, and CNNs for images) learn by adjusting weights; evaluate models with a test set and watch for overfitting.
Frequently asked questions
What is the difference between regression and classification?
Both are supervised learning tasks. Regression predicts a continuous numerical value, such as a price or temperature, while classification predicts a discrete category, such as spam or not spam.
What is clustering?
Clustering is an unsupervised learning technique that groups similar data points together without any labels. A common algorithm is k-means, which assigns each point to the nearest of k cluster centres, and it is used for tasks like customer segmentation.
How does reinforcement learning work?
In reinforcement learning, an agent interacts with an environment by taking actions and receiving rewards or penalties. It learns, through trial and error, the strategy that maximises its cumulative reward over time, which suits game-playing and robotics.
What is a genetic algorithm?
A genetic algorithm is an optimisation method inspired by natural selection. It evolves a population of candidate solutions over generations using selection (keeping the fittest), crossover (combining solutions), and mutation (random tweaks), guided by a fitness function.
What is the difference between an ANN and a CNN?
An artificial neural network (ANN) is a general network of neurons in layers connected by weights. A convolutional neural network (CNN) is a type of ANN that adds convolution and pooling layers to learn spatial patterns, which makes it especially effective for images.
What is the difference between overfitting and underfitting?
Underfitting is when a model is too simple to capture the real pattern, so it performs poorly even on the training data. Overfitting is when a model is too complex and fits the noise in the training data, so it performs well on training data but badly on new data.
Looking for a printable summary? Grab the A4.3 Shuttle Learning revision sheet, a three-page knowledge organiser covering everything above.
Looking for an IB Computer Science tutor?
Hi, I'm Yuness, the tutor behind Shuttle Learning. I work one to one with IB Computer Science students at SL and HL, and I deliberately take on only a handful each year so every student gets my full attention. Most go on to earn the 6s and 7s they were aiming for, in the final exams and the IA alike.
If you would like that kind of support, book a free 15-minute call and tell me what you are stuck on. You can press BOOK A LESSON .